Code that
knows itself.
Stop paying your AI to re-read the same files. AI writes the memory, AI reads it for free — millions of tokens saved.
Never changes your code · self-hosted · no card needed · zero tokens to recall
Stop making your AI think like a human.
A human dev is bound by what they can hold in their head — so we built tools for human limits. An AI isn't. It can hold the whole graph, re-verify a claim in 0.25 ms, and never tire. What it lacks is a project that remembers: the why behind every line, the decisions it must not undo, the real names of things.
recall gives it exactly that — a codebase with memory, a conscience, and a track record. Free the AI from human restrictions, give it the context only the project can hold, and it codes the way it actually can: creative, exact, and fast. The AI are the hands; the project is the coworker.
One idea, six consequences — follow the chain“…but what does it do to my code?”
Nothing. recall never changes a single line.
It only reads. Everything recall knows lives in a local .mind/ index and in your commit messages — never in your source. No reformatting, no refactor, no edits, no files moved. Delete .mind/ any time and your repo is byte-for-byte what it was.
The code is the only truth.
Knowledge lives beside the code — in a wiki, a ticket, a chat window. The code itself stays flat and silent, so the instant it changes, the doc starts to lie.
recall keeps the knowledge in the code: pinned to the commit that changed it. One source of truth, not two that drift apart.
One truth in the code — so everything below follows from it.
Read: why it all connectsCaptured when the AI still knows.
The expensive thinking happens while the bug is being fixed — then it evaporates. Later, someone (or some AI) has to re-derive the why from cold syntax.
While the AI works and the context is still in its head, recall stamps the decision + the why + the anchors onto the commit. Cheap, exact, one sentence.
$ git commit -m "switch seat check to an atomic RPC
Recall-Why: the JS check-then-insert raced under load and
double-booked the last seat; the RPC locks the org row.
Recall-Anchors: seats, confirmSeatOrRollback, orgs.ts"The why is written at the knowing moment — so reading it back needs no model.
Read: write-time stampingA reader so dumb it's free.
Every “why is this here?” makes the AI grep and re-read whole files — tens of thousands of tokens per question, paid again every session.
Because the meaning was written at write-time, reading is a plain SQLite + FTS5 lookup — no model, no embeddings. The finished answer in sub-milliseconds.
- grep the codebase for the symbols
- open + read 3 candidate files top to bottom
- re-derive the reasoning from scratch — every turn
- one SQLite lookup over the stamped anchors
- returns the decision + the why + the links
- pinned to a commit — traceable, freshness-checked
Orienting is free — so you can afford to read the whole picture, every time.
Read: the architectureSix answers, before the first keystroke.
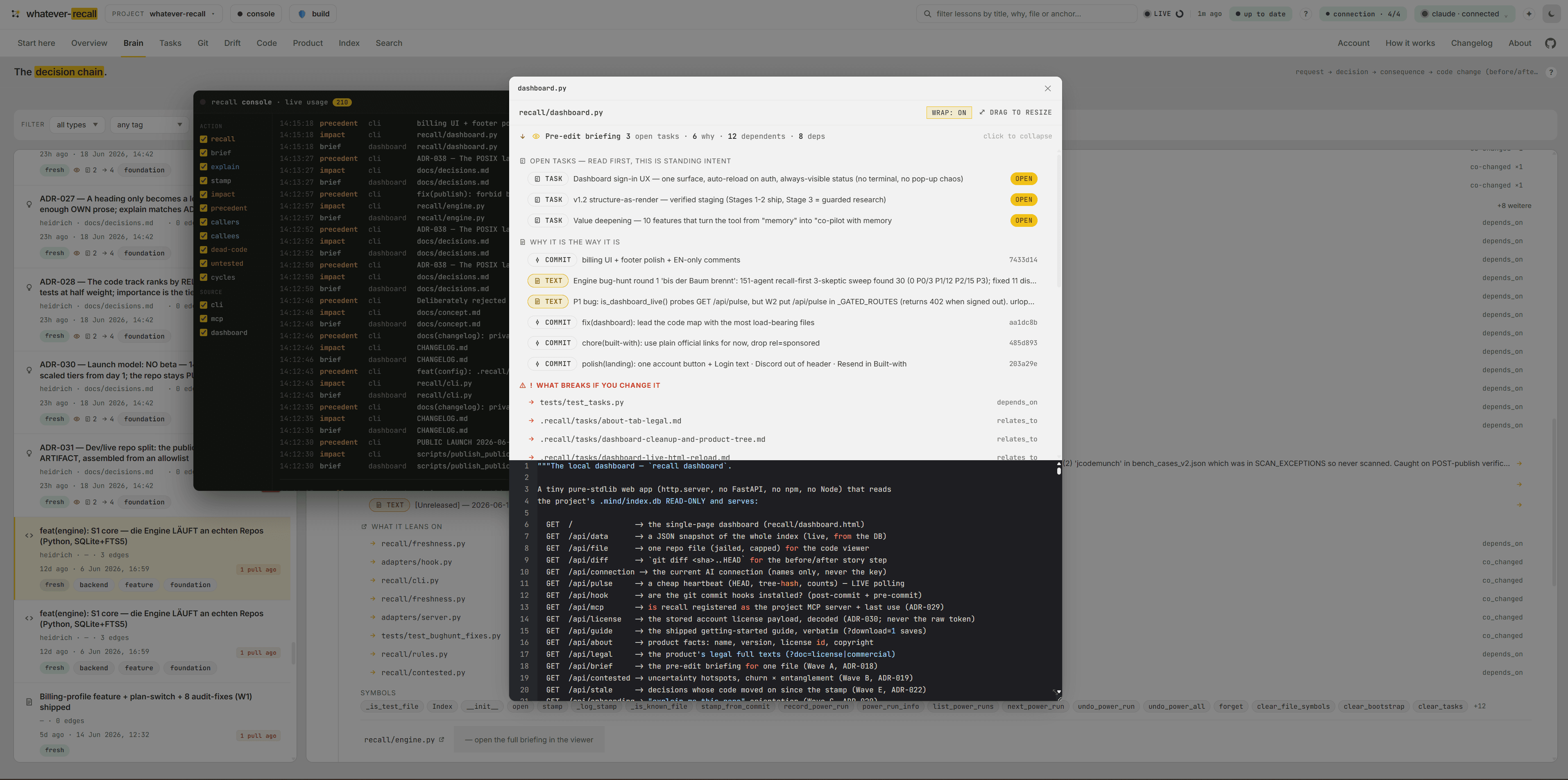
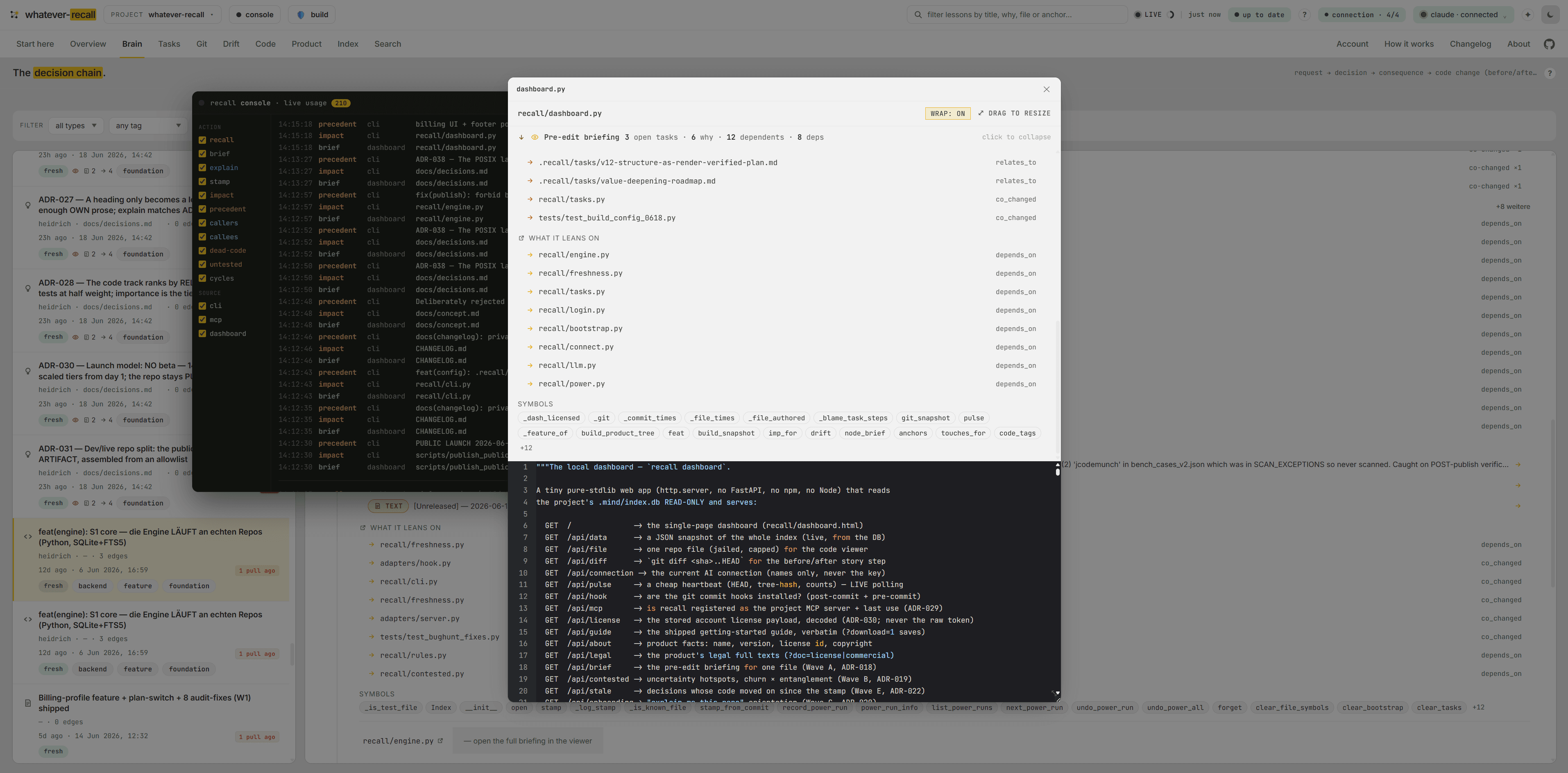
An AI opens a file blind — it can't see the open task wired to it, the decision it's about to undo, or what its change will break three files away.
One recall brief answers six questions at once — what · where · why · what breaks · open tasks · the trail — read-only, 0 tokens, the full profile of a file.
kind: api-route · POSTread more →orgs.ts · confirmSeatOrRollback()read more →“atomic RPC — the JS check raced” @a1b2c3read more →7 depend on this · leans on 3read more →▸ TASK: migrate seats to RPC (open)read more →billing → seats → license gateread more →The whole picture is affordable — so an AI never silently undoes a decision it never saw.
Read: the 6 dimensionsThe code knows what it's called. Your AI doesn't.
An AI invents a symbol name from its training — enforceSeats? seatLimit? — greps this repo, misses (blind grep lands 0 of 12), and burns the loop guessing again.
recall doesn't make the search better — it turns it around. It already wrote down this repo's real vocabulary at write-time, so it corrects the guess into the real name before the grep runs.
- invents a plausible name —
getUserSession() - greps this repo for it — 0 hits
- guesses again, re-reads files, burns tokens
- ranks the guess by the repo's own vocabulary
- corrects it —
getUserSession()→resolveActiveSeat() - the grep lands first try, no tokens wasted
The idea is straight from the support trenches: a senior agent doesn't answer faster, they make sure the question is asked so it can't be misunderstood. recall does that for your AI — it structures the question against the repo's real words before a single token is spent guessing.
We fix the question, not the answer — the code becomes the senior support agent for the AI.
Read: search-inversionThe memory gets truer the more you work.
Docs rot because nobody notices when reality diverges from them. Six months in, most of the wiki is wrong and nobody trusts any of it.
Every note is pinned to a SHA. When the code beneath it moves, recall flags the drift (🟡) and offers the fix at the next commit — you approve, the truth stays current. It only flags, never silently rewrites.
- nothing checks the note against the code
- the AI reads the rotten version
- and confidently builds the wrong thing
- SHA-pinned, so drift is detectable
- recall offers a fix or supersede — you decide
- you approve — the old decision stays in history
Drift is caught and you approve the fix — and that feeds back into write-time, so the brain compounds. ↻ the loop closes — every commit makes the next one smarter.
Read: catch the drift & the loop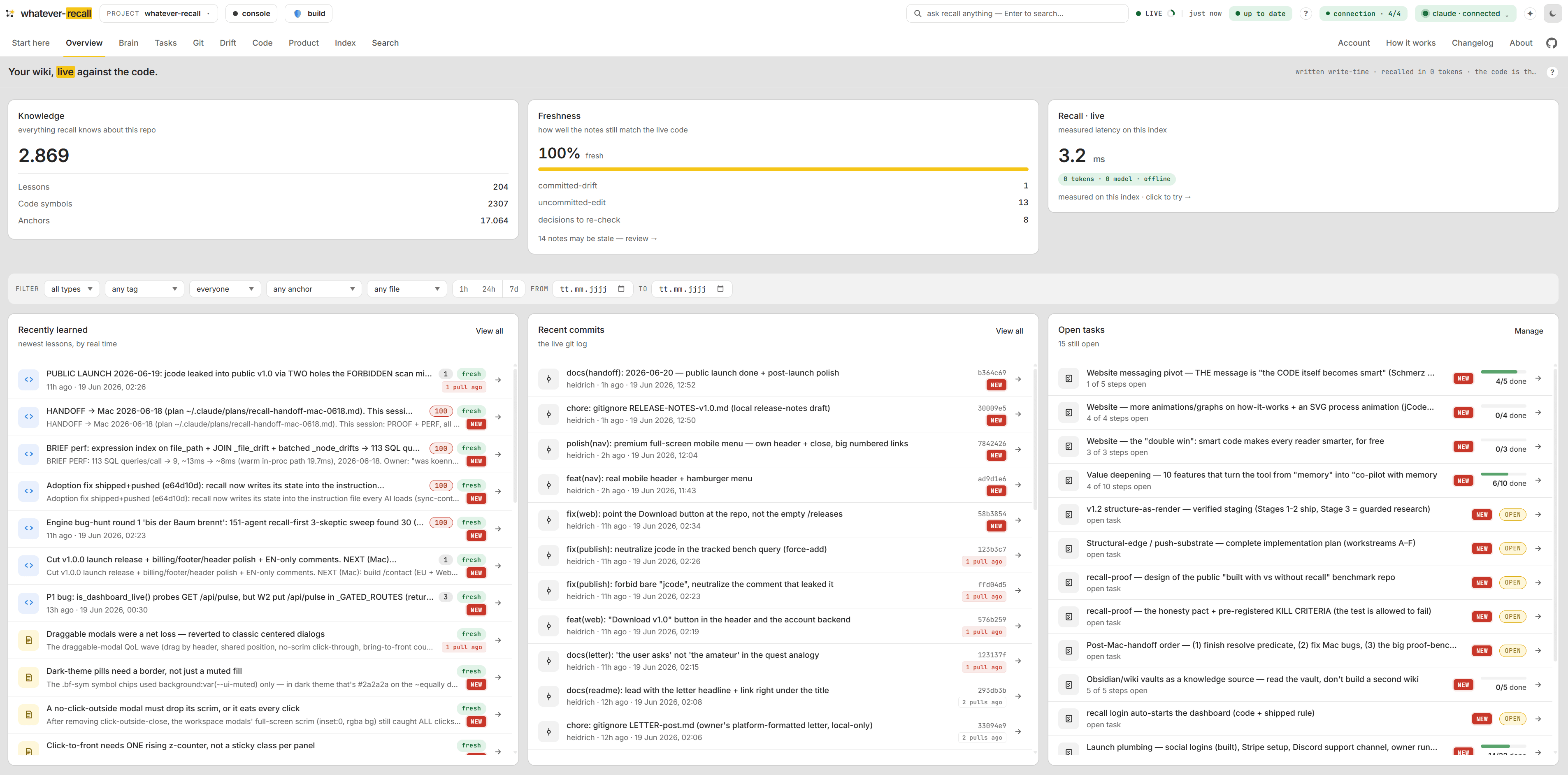

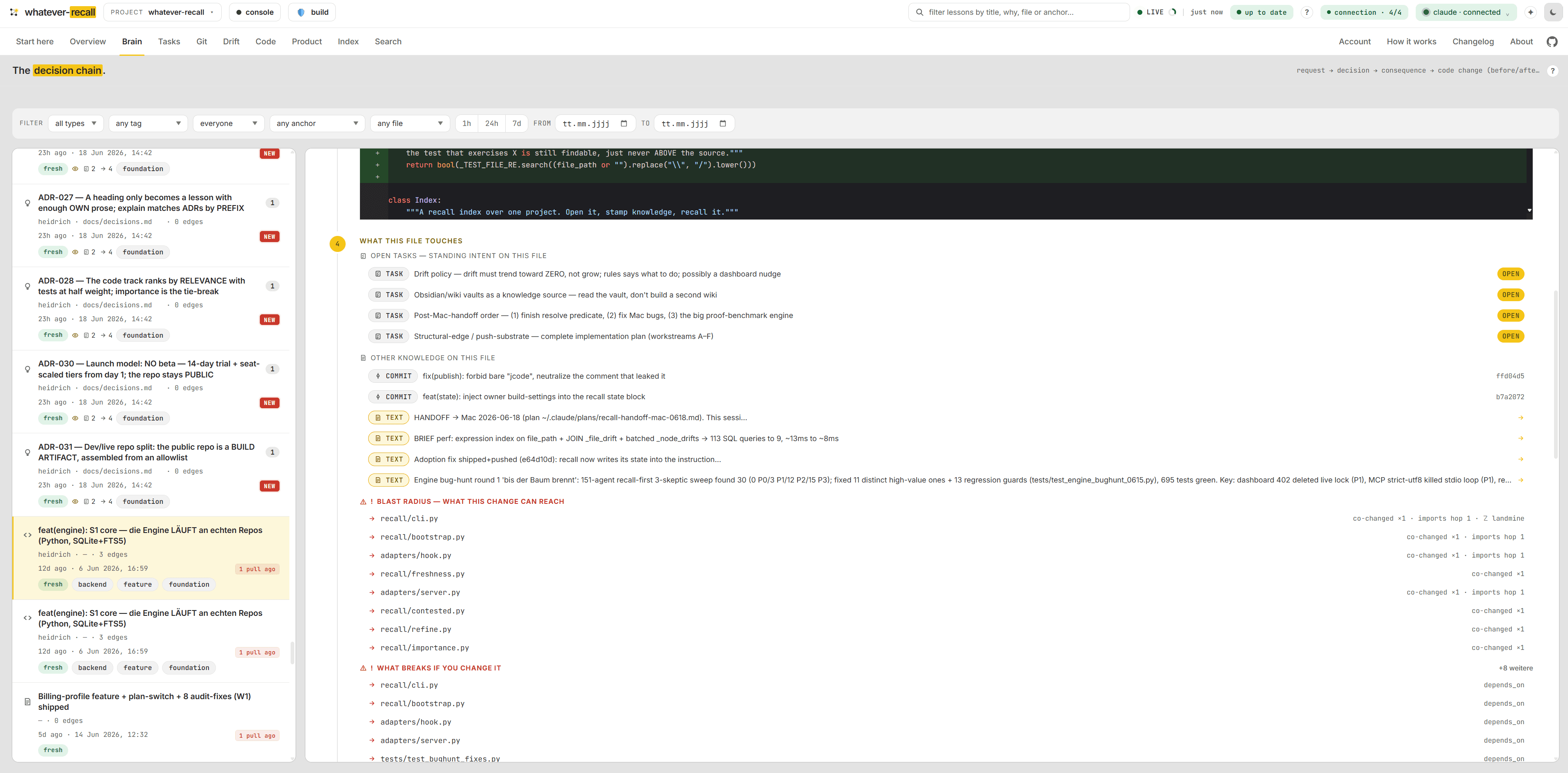
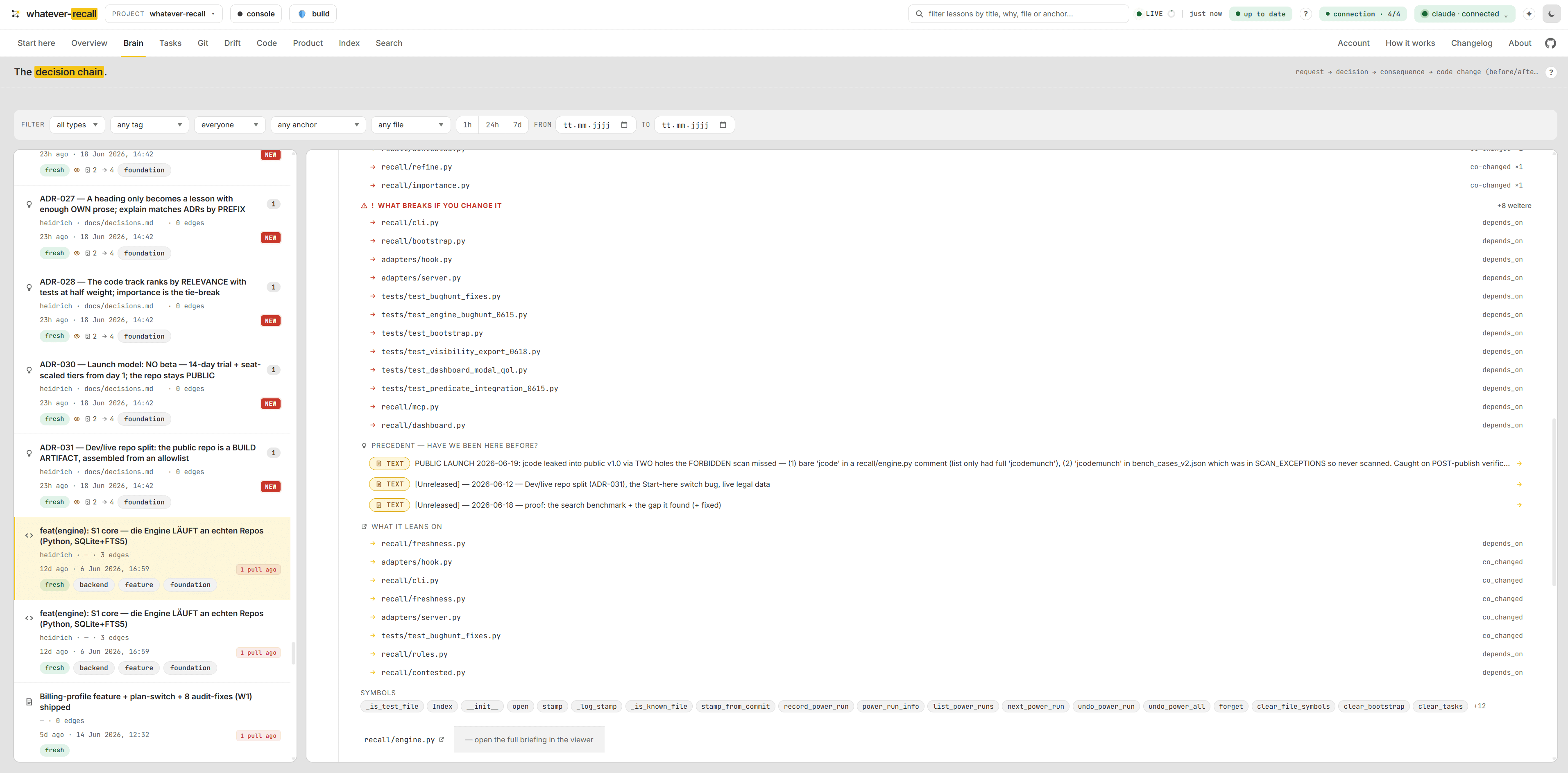
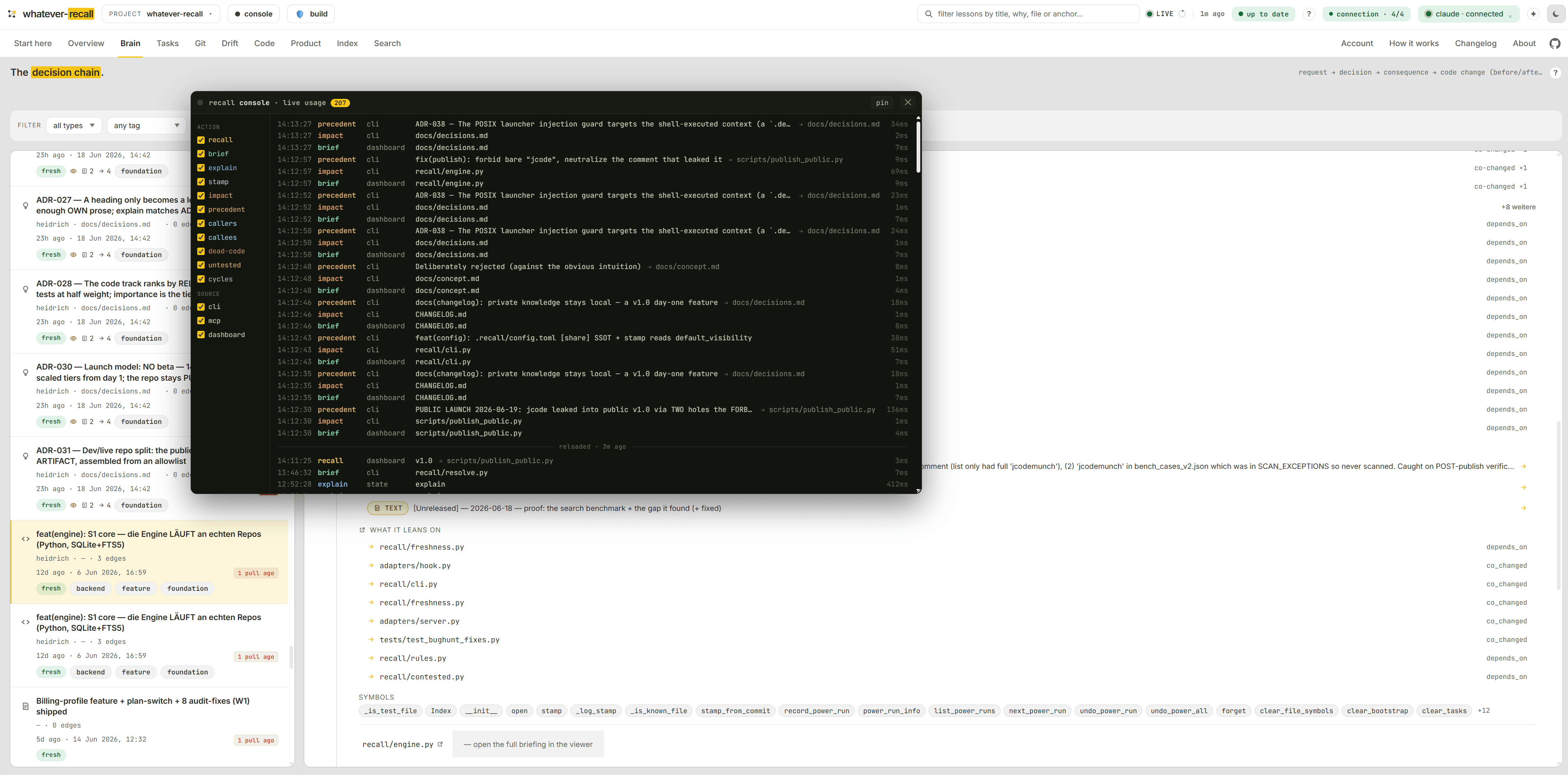
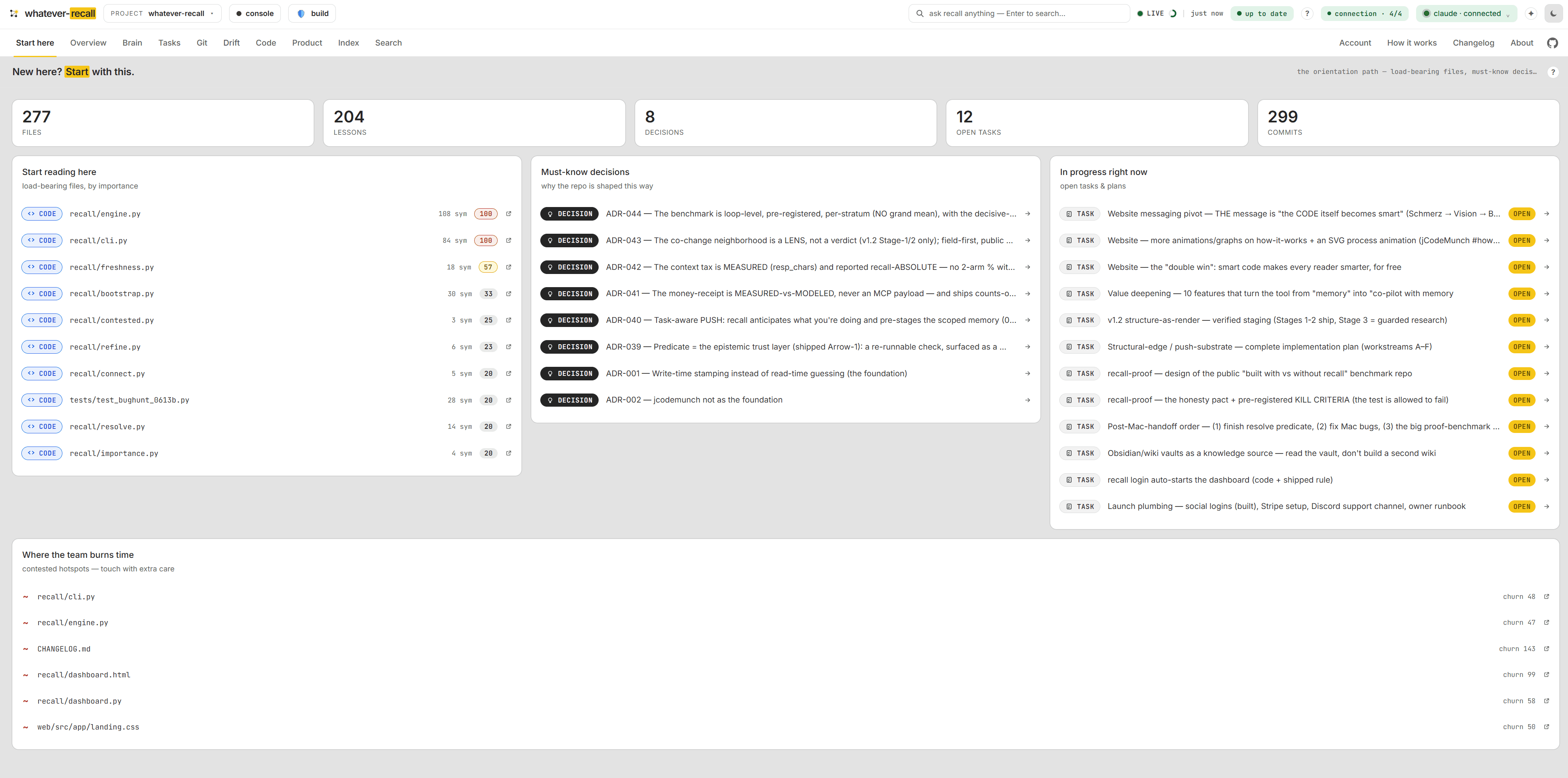

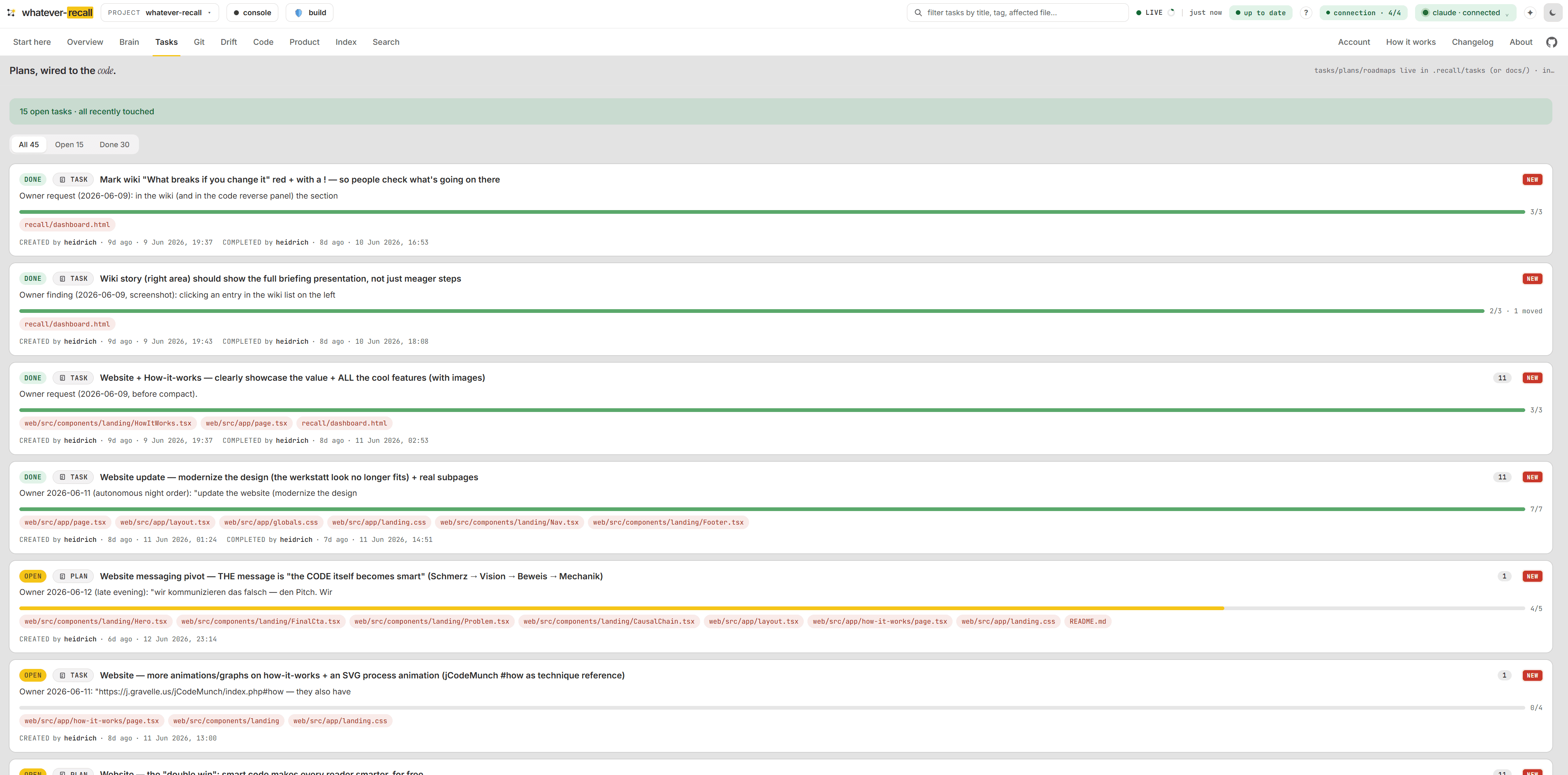
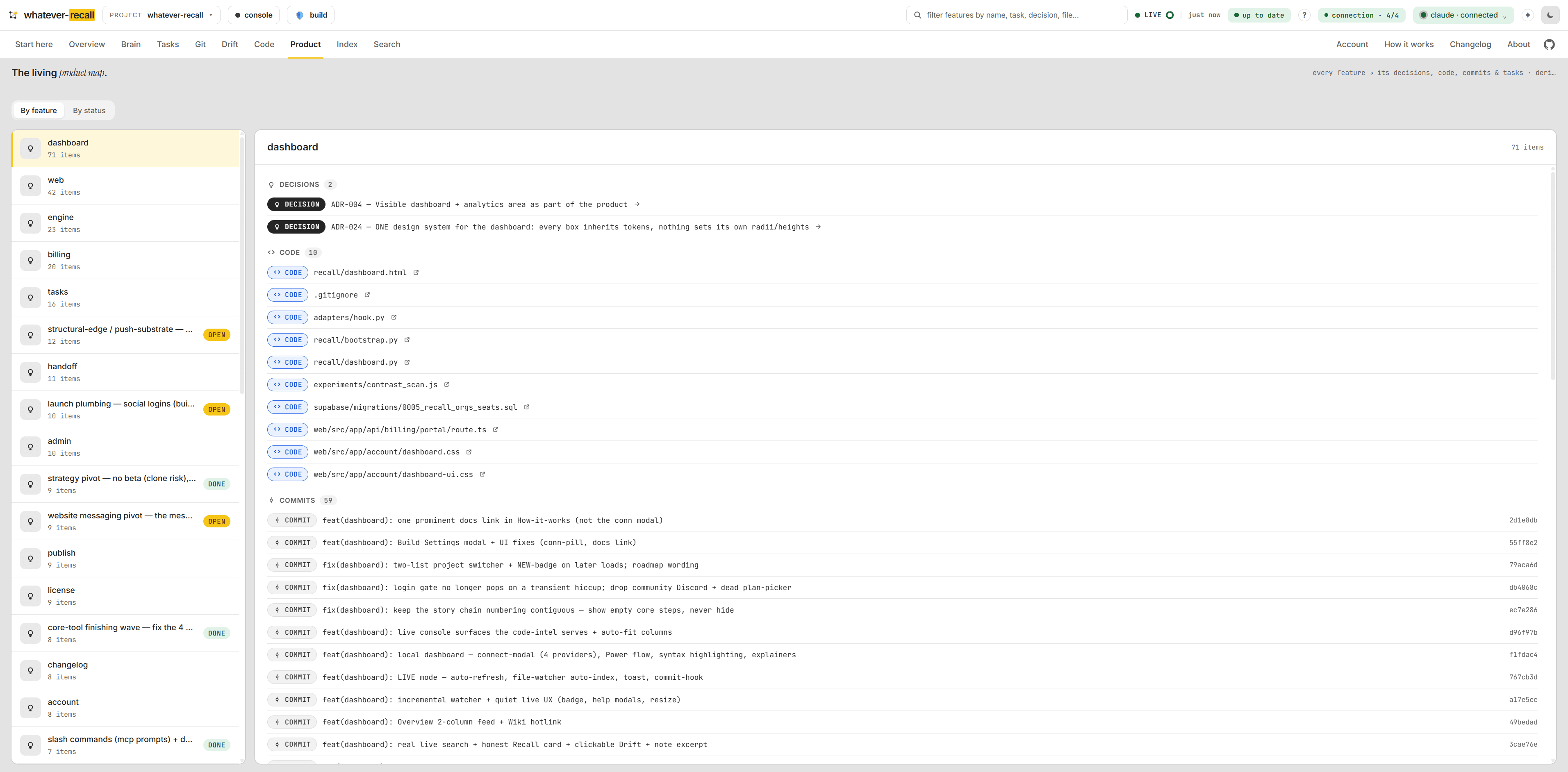
The live pulse — knowledge, freshness, recall.
Your wiki measured against the code: knowledge, a freshness score and recall at a glance, with the latest lessons, commits and open tasks streaming in. Derived from the repo, always current, zero tokens to read.
The token bill is
the whole story.
For an AI, context space is the scarce resource. grep finds where a word sits — to learn why, it must read whole files back into context, tens of thousands of tokens per question. recall returns the decision in ~56. Measured cold-start on two live production repos (a 240-commit app, a 668-commit CMS), no recall trailers planted — that gap is the product.
| Method | Time | Tokens | The why? |
|---|---|---|---|
| recall() | 2.18 ms | ~152 | ✓ direct |
| git grep + read files | 147 ms | ~214,000 | ✗ only where |
| code-index search | ~seconds | — | ✗ 0 hits · 2d stale |
| Question | grep+read | recall |
|---|---|---|
| Why must RLS writers set workspace_id? | 48,200 | 56 |
| Why split the viewer from the editor? | 71,500 | 61 |
| Why render the search modal via createPortal? | 39,800 | 52 |
| Repo | Anchors | Median | Max |
|---|---|---|---|
| fixture | 1,204 | 0.04 ms | 0.09 ms |
| production app | 43,722 | 0.41 ms | 0.67 ms |
| production CMS | 108,627 | 0.68 ms | 1.0 ms |
The whole chain,
paid back in your bill.
Six links, one outcome: the AI finally has what it needs to do its best work, and the company stops paying for it to guess. Here's what lands on the balance sheet.
Millions of tokens saved
152 vs ~214,000 tokens for the same three answers, measured. Across a team, across a year, that read-time saving scales into the millions — every orientation that used to cost a model call is now free.
Memory that compounds as you work
The loop compounds: every commit stamps new knowledge and flags old drift for you to resolve, so the most-worked code carries the truest memory. The longer it lives, the smarter it gets.
Faster results, fewer mistakes
The AI is briefed before it edits and warned before it repeats a known mistake — so it stops re-deriving, stops hallucinating constraints, and stops undoing decisions it never saw.
Searches that land first try
Search-inversion fixes the guessed name to the repo's real vocabulary before the grep — no more guess → miss → guess loop burning tokens and wall-clock.
Sharper analysis & onboarding
Blast radius, contested hotspots, the causal trail — and a new dev or a fresh agent inherits the whole repo's reasoning in one command.
Local, offline, one tool
Your code and memory never leave your machine — no cloud, no telemetry, no vector DB, no API key. One small tool, pure stdlib, runs with the network cable pulled.
Your code never
leaves your machine.
recall is a small, self-hosted tool — not a platform. It needs exactly one thing: access to your project folder. That's the whole footprint, and the whole setup takes two minutes.
Runs on your machine
A small CLI and a local index inside your repo (.mind/). No server to run, no agent in the background. Works offline between hourly licence checks (a brief online confirmation, with a short grace window) — your code never leaves your machine.
No data sync. Ever.
Nothing is uploaded, nothing is synced, no telemetry. It only reads your project — the website just checks your license.
Open code — maximum trust
The full source is public on GitHub. Read every line that touches your repo before you run it.
$ pip install git+https://github.com/heidrich/whatever-recall.git
$ recall init .
# indexed — your repo is its own memory nowThat's it. No config, no cloud account, no upload — the memory lives in your repo and ships with every clone. Questions? The source on GitHub is one click away.
Your decisions never
leave your machine.
The most sensitive thing about a codebase is the why behind it. recall keeps it in a local brain, not in your source — so your code ships clean, and your reasoning stays yours unless you choose to share it.
The why lives in the brain, not your code
Every decision you stamp sits in the local .mind/ index — beside your code, never inside it. Your source ships byte-for-byte clean; there's nothing to scrub before you publish.
Per-note visibility: team or private
Mark a note --private and it's yours alone — never in an export, never in a shared brain. Notes can only get more private, never less. You can't widen something by accident.
Share a brain — without leaking
recall export writes a shareable copy with every private note stripped out. Whether your team shares it is your call; what's in it is recall's guarantee: team knowledge, never private.
Two guards, both fail-closed
The export aborts rather than write a brain that still holds a private note, and check-leak blocks a commit that would stage one. A private decision physically can't reach a teammate's clone or a public repo.
$ recall stamp "why we chose this" --private
🔒 private — stays in this brain
$ recall export --out .mind/shared.db
# private notes stripped · gate verified cleanA solo developer ships a clean codebase by construction. A team shares the knowledge it wants to — and nothing it doesn't. Your code is the public artifact; your reasoning is yours. How private knowledge stays local →
One product.
Priced by seats.
No tiers, no feature locks, no “upgrade to unlock.” Everyone gets every feature — the CLI, the dashboard, Power Mode, the web-AI bridge, MCP, unlimited repos. You only choose how many people share the memory. Buy a single seat and run solo, or add seats and the team tools appear. Try all of it free for 14 days — no card.
1 seat = run solo. Add a 2nd to unlock team tools (members, keys, billing).
Start 14-day trial→No card. Every feature. Cancel anytime.
- The CLI, the dashboard, MCP & git hooks
- Power Mode & the web-AI bridge
- Token-free recall — reads cost zero model tokens
- Works offline between hourly seat checks (a short grace if a check can't reach us)
- Unlimited repositories, unlimited stamps
- Self-hosted — your code & memory never leave your machine
- Team tools at 2+ seats: members, license keys, shared billing
- Every new release becomes open source (Apache 2.0) after 3 years
The same product whether you're one developer or a hundred — the only thing that scales is the number of people sharing the memory.
I firmly believe that education — and exploring and debating problems together — is the best way to lead humanity into a fantastic future.
So schools and universities use recall for teaching and academic research at no charge — no fees, ever. We'd love to hear what you're building. The one honest line: if the research becomes a product or spin-off that earns money, it needs a regular plan from that point on.
14-day trial, full features, no credit card. Self-hosted either way — your code and your memory never leave your machine; the account only carries your license. Licensed under the Business Source License 1.1 — every released version becomes open source (Apache 2.0) three years after its release, so your stack can never end up in a proprietary dead end.
“We document constantly, then change the plan and never update the doc. The memory rots, the AI reads the rotten version and builds the wrong thing. So we moved the truth into the code itself — the one thing that can't lie.”
A smart AI greps a name it invented.
Smart, self-aware code knows it.
recall fixes the guess to your repo's real vocabulary before the search — because it's the only thing that recorded what you actually call things.
It's time to unlock the full power of AI coding.
The foundation is real today — the code becomes self-aware, reading is free, the search stops guessing. From there we harden on your feedback, then open it up into a real app with deeper features. The horizon we're building toward (not shipped yet, and we'll always say so plainly): today your code lives in folders and files built for human reading. An AI navigates the graph, not the tree — and recall already holds that graph. The idea turns it around: the graph as the truth, the file layout as a view rendered from it, so an AI can structure code the way it thinks while recall renders it back to ordinary files for your compiler and git. It starts small — recall suggesting where code really belongs.
Read where recall is going