How recall works.
The code itself becomes smart: the decision, the why and the links are stamped at write-time — the moment the AI already knows. Reading it back costs zero tokens, takes milliseconds, and can't drift, because the code is the memory.
Intelligence at the
knowing moment.
Most tools try to be clever when you ask (read-time) — and guess. recall is clever when the AI writes (write-time) — when it actually knows. The reader can then be dead-dumb: zero tokens, sub-millisecond, and it returns what was actually written down — not a guess.
Stamped when the AI already knows.
The intelligence moves from the guessing moment (read-time) to the knowing moment (write-time). While the AI works, it stamps a tiny anchor onto the commit — the decision, the why, the links.
Three levels, every query.
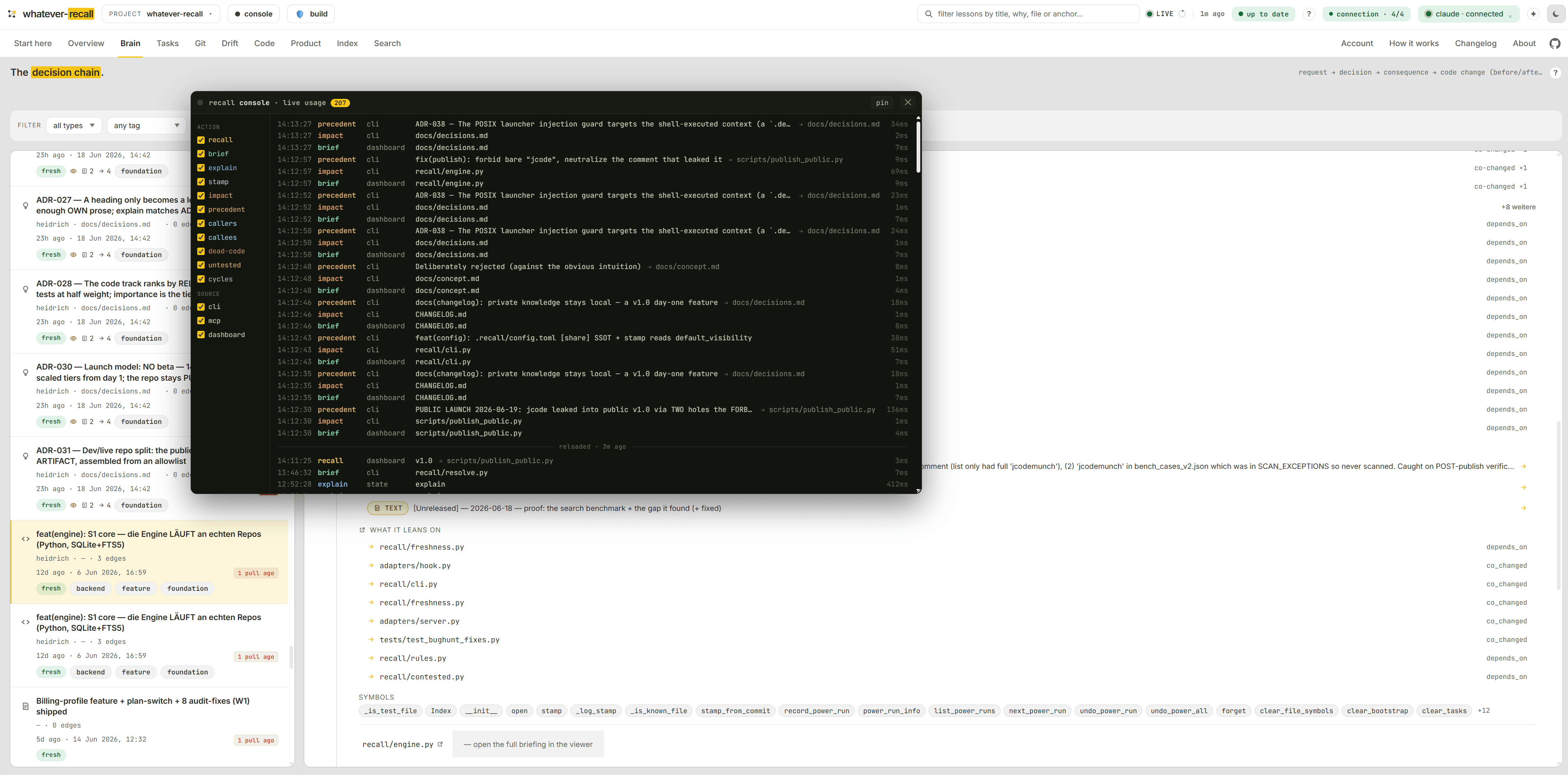
Ask a question and recall returns the hit, the meaning (the why), and the relation (what it links to) — via a recursive graph walk over the anchors. Not where a word appears: the decision itself.
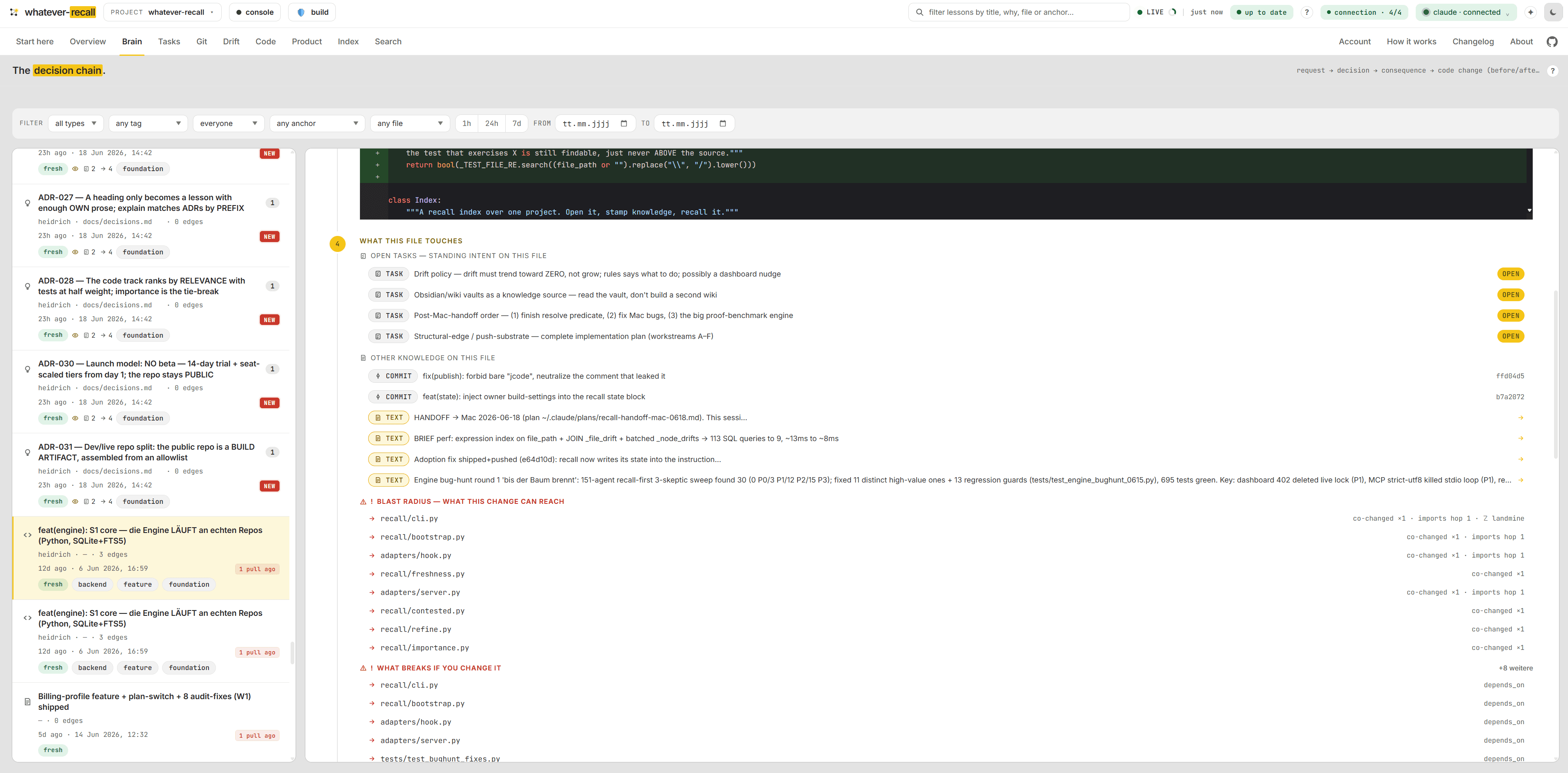
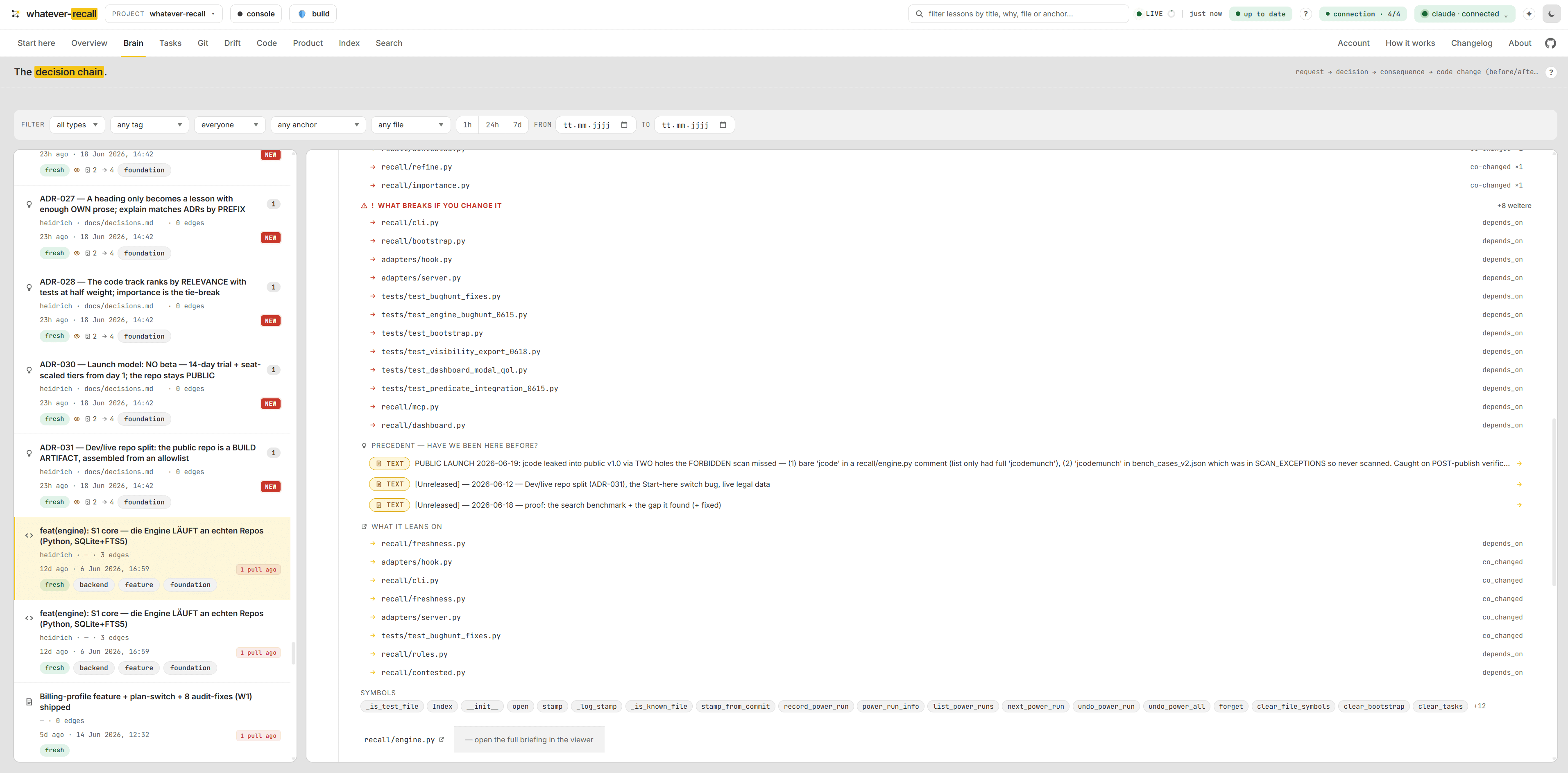
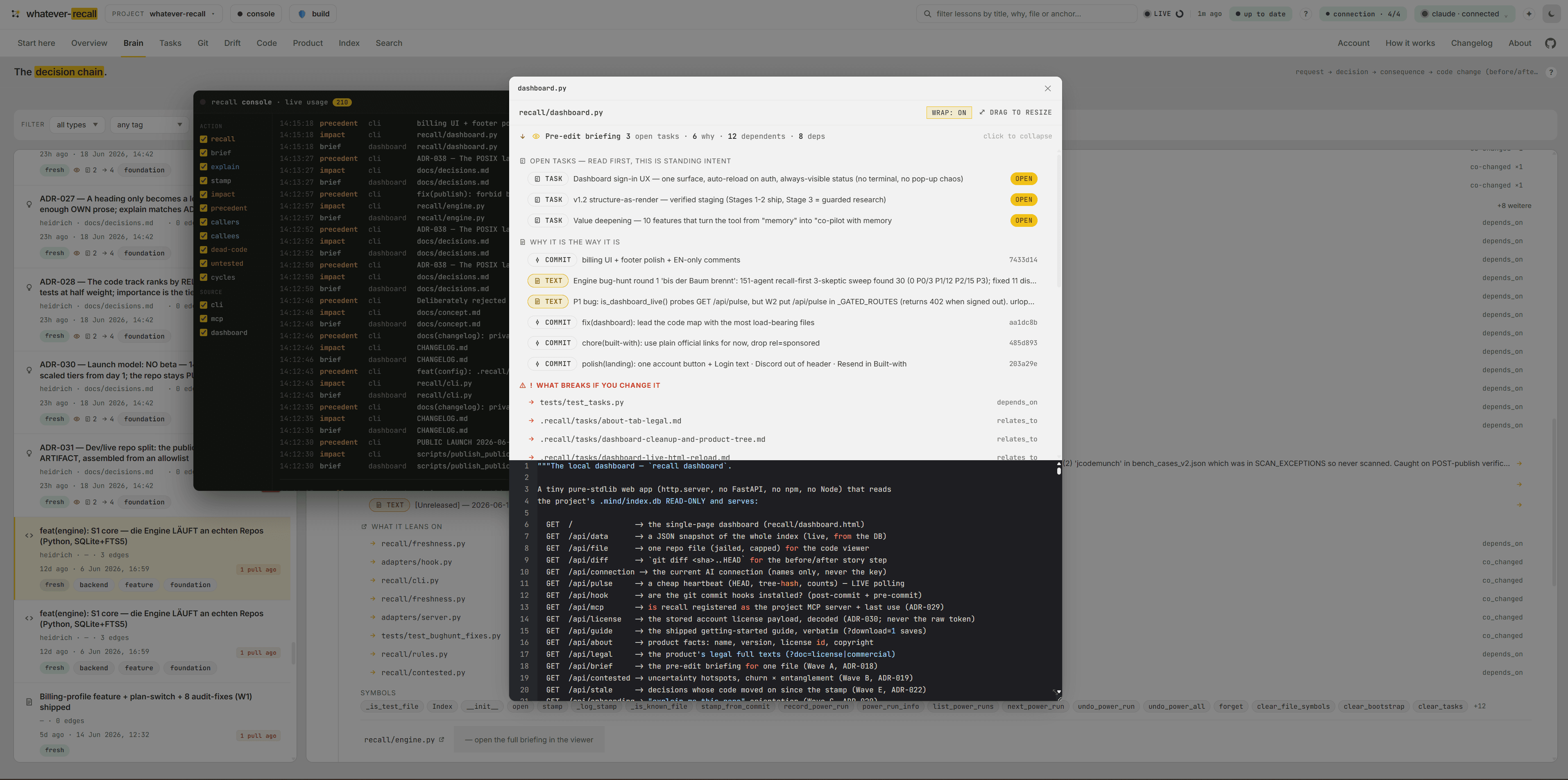
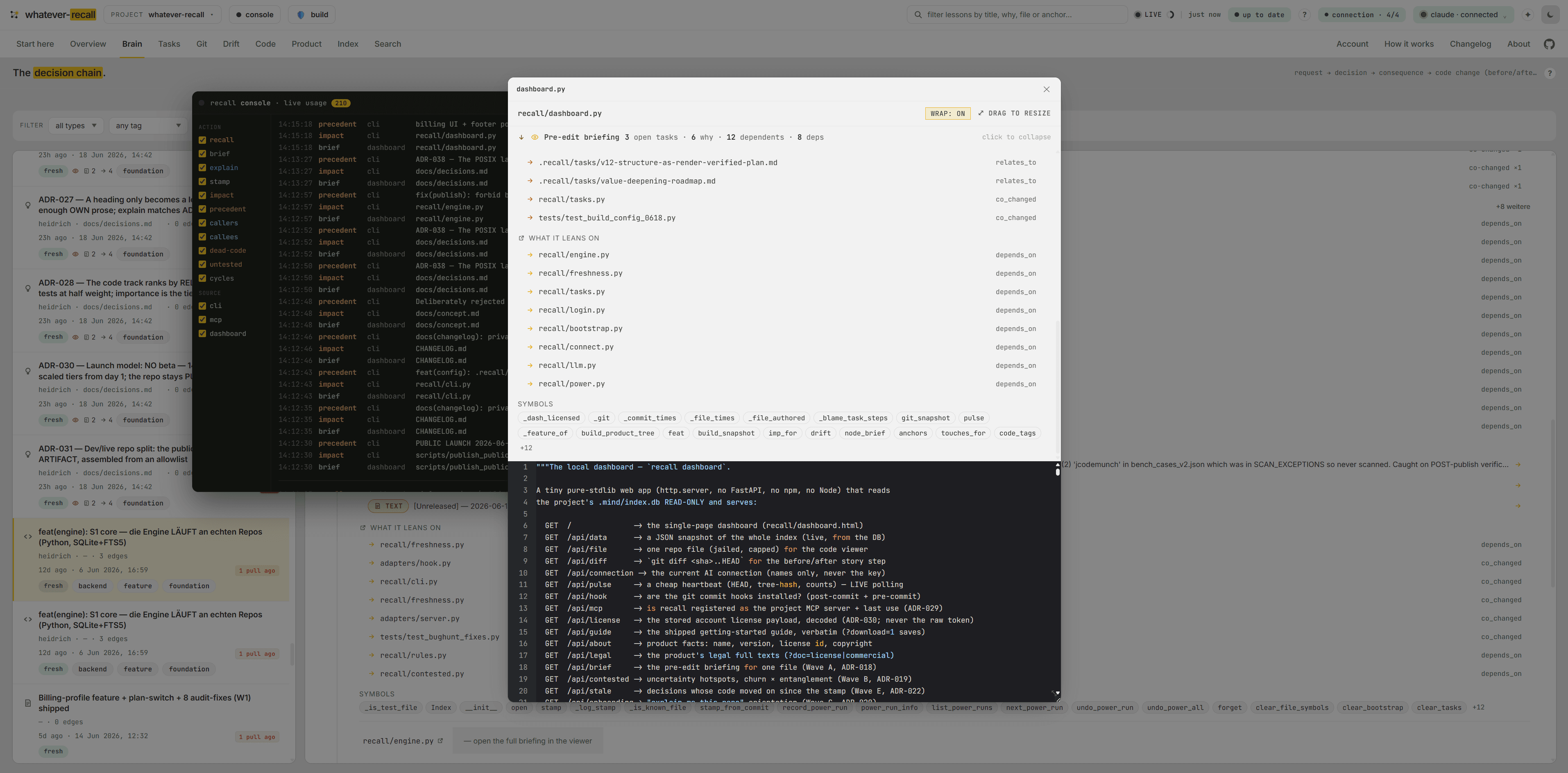
Before you touch a file, you’re briefed.
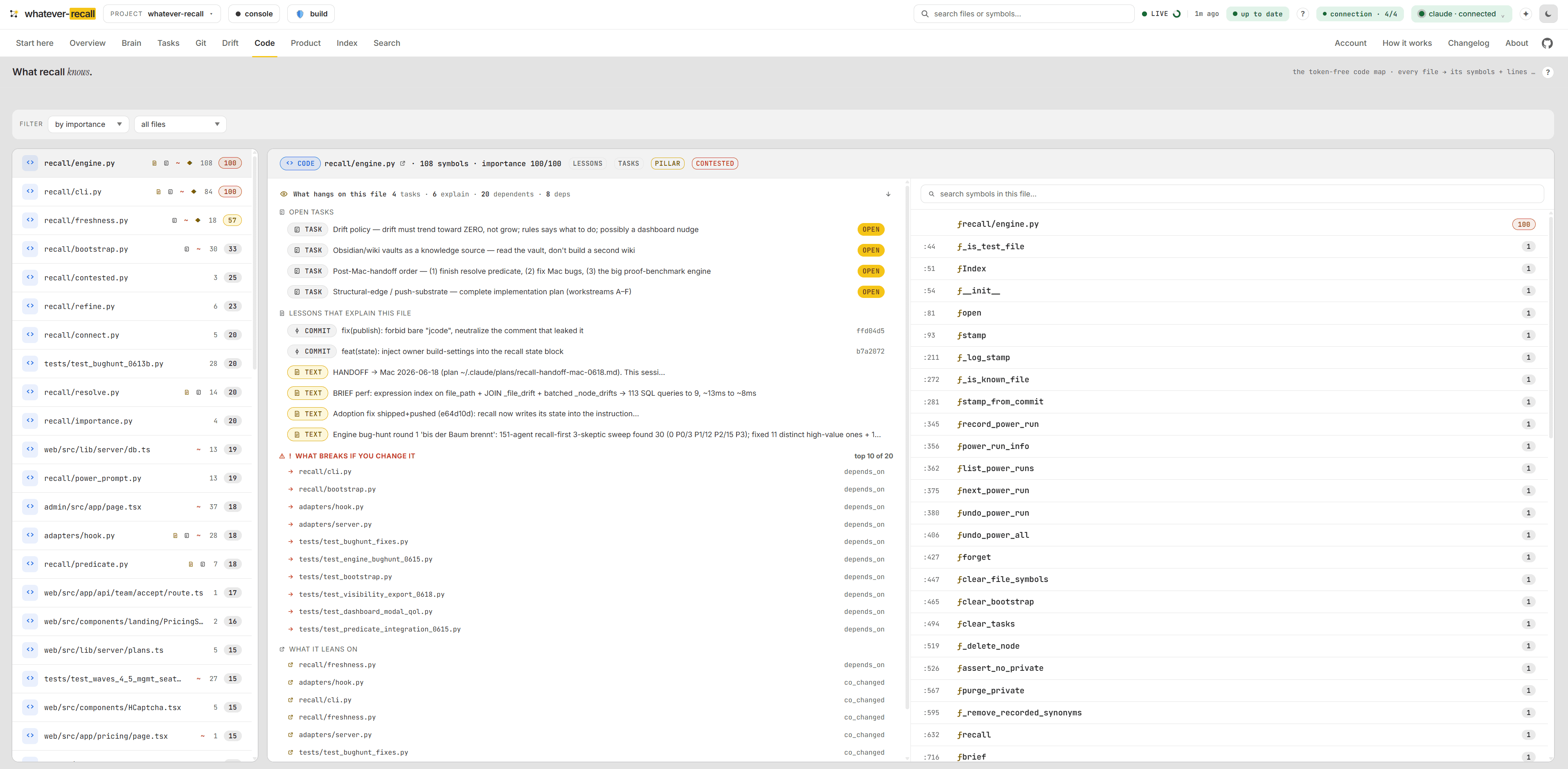
Ask recall about one file and — read-only, zero tokens — it bundles the open tasks wired to it (standing intent), why it is the way it is, what breaks if you change it (the blast radius), and what it leans on. So an AI never silently undoes a decision it never saw. The IDE hook injects it before every edit.
Where the team burns time.
recall ranks the files the team keeps rewriting — churn × entanglement (how often it changes, with how many other files at once). A load-bearing file written once is important; a tenth-rewrite is where the uncertainty lives. The places to touch with extra care.
A reader so dumb it’s free.
Recall is plain SQLite full-text search — no embedding model, no LLM in the read path. The intelligence was spent once, at write-time. Reading it back is free and instant, forever.
Smart from minute one.
Point recall at an existing repo and it builds a base intelligence token-free — from your git history, a tree-sitter code map, and the docs you already wrote (CHANGELOG, ADRs, MEMORY). No cold start.
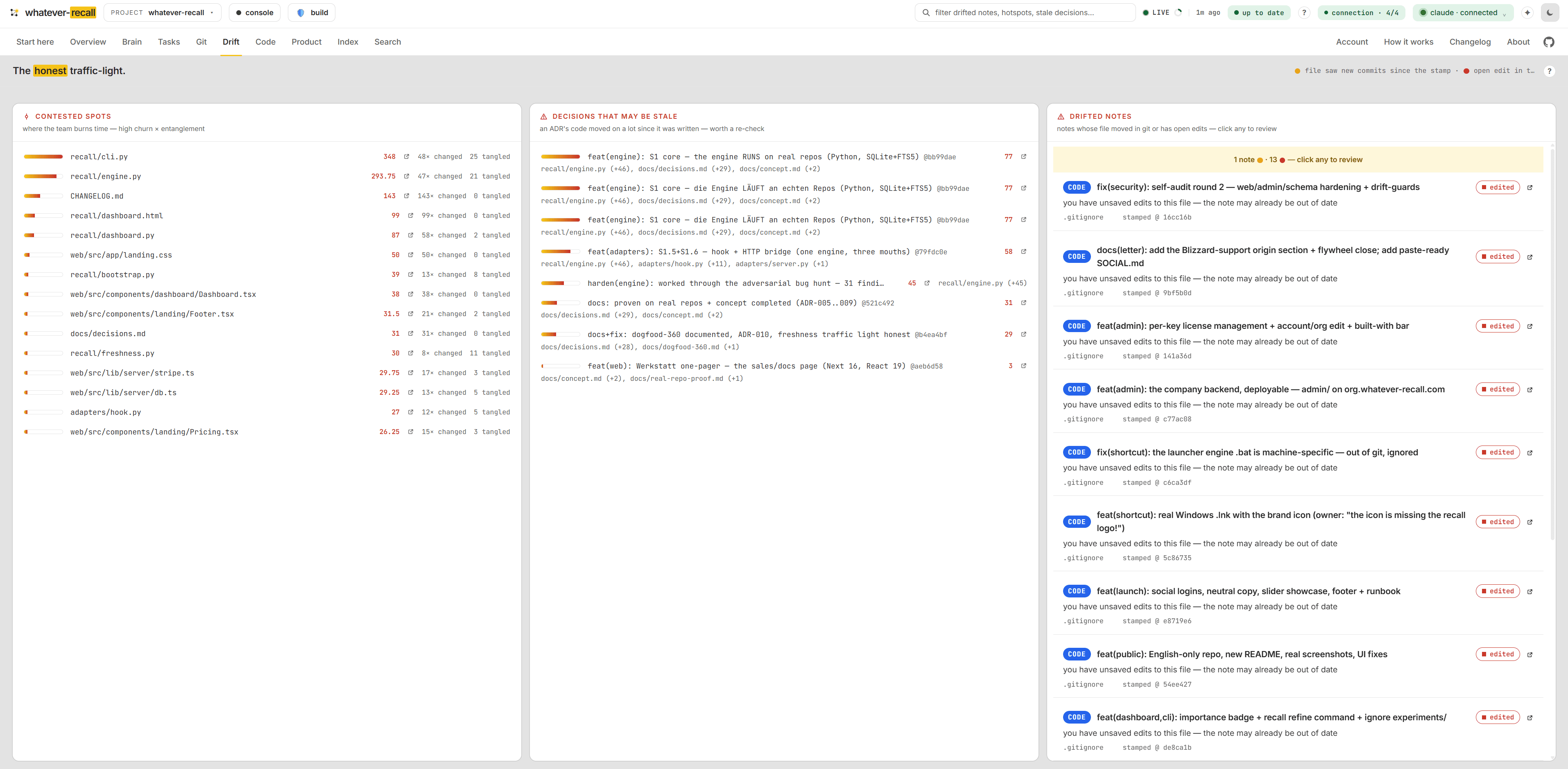
It knows when it’s stale.
Every note is pinned to a SHA. When the code beneath it moves, recall marks the note 🟡 instead of silently serving an old answer — the exact failure mode that rots every doc.
Smarter on every commit.
Each commit auto-wires new links into the graph. Human commits get wired retroactively. The system compounds: the more you ship, the sharper its memory of why you shipped it.
Make the code smart.
Then read it for free.
Version control remembers what. Your code now remembers why. recall spends the intelligence once, at write-time, so reading it back can be dead-dumb — and a dumb reader is the fast, precise, cheap, traceable one. The ~1,400× token saving falls out of that — it isn’t the trick, it’s the receipt.
Make the system smarter — once, at write-time.
While the AI works and already knows why, it stamps one sentence onto the commit: the decision, the why, the links. The thinking happens at the knowing moment, not the guessing moment. The codebase itself gets smarter.
Now the reader can be dead-dumb.
Because the intelligence is already in the index, recall doesn’t reason at read-time at all — it’s plain SQLite full-text search. No model, no embeddings, no re-reading files. A reader so dumb it costs nothing to run.
And a dumb reader is the fast, precise, cheap one.
It returns the exact decision (precise, not “where a word appears”), in sub-milliseconds (fast), for zero model tokens (cheap) — and the harder and more complex the question, the bigger the win, because a dumb lookup stays flat while grep-and-read explodes.
Every answer is traceable — and can’t go stale.
Each note is pinned to the commit it was written against, so you can follow any answer back to its source, and recall flags it the moment the code moves on. Nachvollziehbar by construction: the code is the memory, so the memory can’t lie.
The RLS cut-over — one commit touched the storage writer; every write now runs under row-level security.
The stamped decision: service-role writes bypass RLS — the writer itself must set workspace_id, or the row is invisible.
Five files depend on the writer — uploads, sync, the importer. The blast radius lists every one before you touch it.
Pinned to its commit. recall re-checks it against today's code: 🟢 still true — if the code moves on, the answer is flagged, never silently wrong.
— what · why · how · when — answered from the code itself · on every edit · passively —
- grep the codebase for the symbols
- open + read 3 candidate files, top to bottom
- re-derive the reasoning from scratch — every turn
- one SQLite lookup over the stamped anchors
- returns the decision + the why + the links
- pinned to a commit — traceable, freshness-checked
Measured cold-start on two live production repos (a 240-commit app, a 668-commit CMS) — three real questions, no recall trailers planted. ~1,400× fewer tokens, ~67× faster — and the harder the question, the wider the gap, because the dumb lookup stays flat while grep-and-read keeps re-reading.
The token bill is
the whole story.
For an AI, context space is the scarce resource. grep finds where a word sits — to learn why, it must read whole files back into context, tens of thousands of tokens per question. recall returns the decision in ~56. Measured cold-start on two live production repos (a 240-commit app, a 668-commit CMS), no recall trailers planted — that gap is the product.
| Method | Time | Tokens | The why? |
|---|---|---|---|
| recall() | 2.18 ms | ~152 | ✓ direct |
| git grep + read files | 147 ms | ~214,000 | ✗ only where |
| code-index search | ~seconds | — | ✗ 0 hits · 2d stale |
| Question | grep+read | recall |
|---|---|---|
| Why must RLS writers set workspace_id? | 48,200 | 56 |
| Why split the viewer from the editor? | 71,500 | 61 |
| Why render the search modal via createPortal? | 39,800 | 52 |
| Repo | Anchors | Median | Max |
|---|---|---|---|
| fixture | 1,204 | 0.04 ms | 0.09 ms |
| production app | 43,722 | 0.41 ms | 0.67 ms |
| production CMS | 108,627 | 0.68 ms | 1.0 ms |
Not where a word
sits. The decision.
One query, three levels: the hit, the meaning behind it, and what it's wired to. This is the exact shape recall returns — pinned to a commit, freshness-checked, in under a millisecond.
Now you can trace
everything.
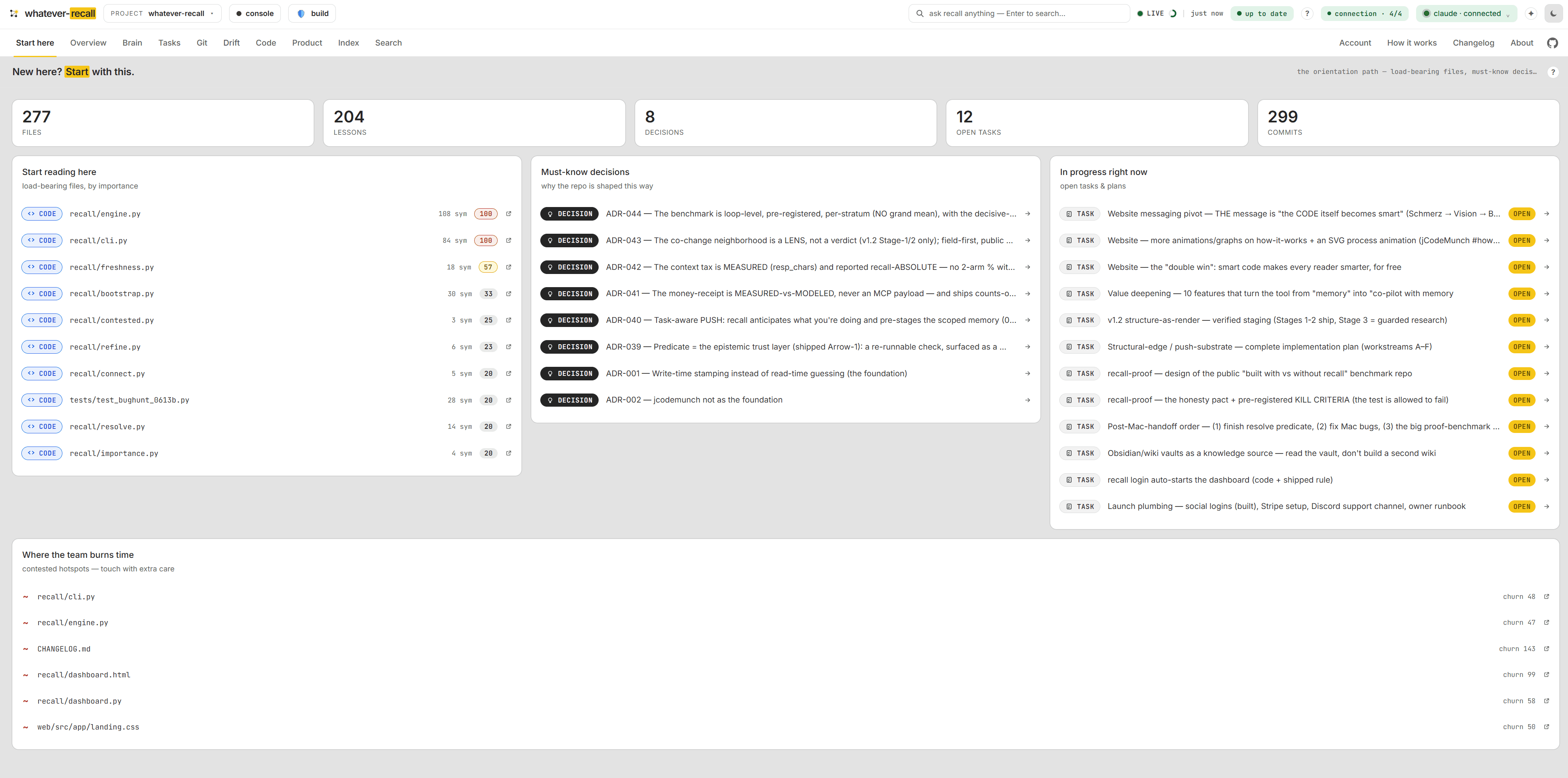
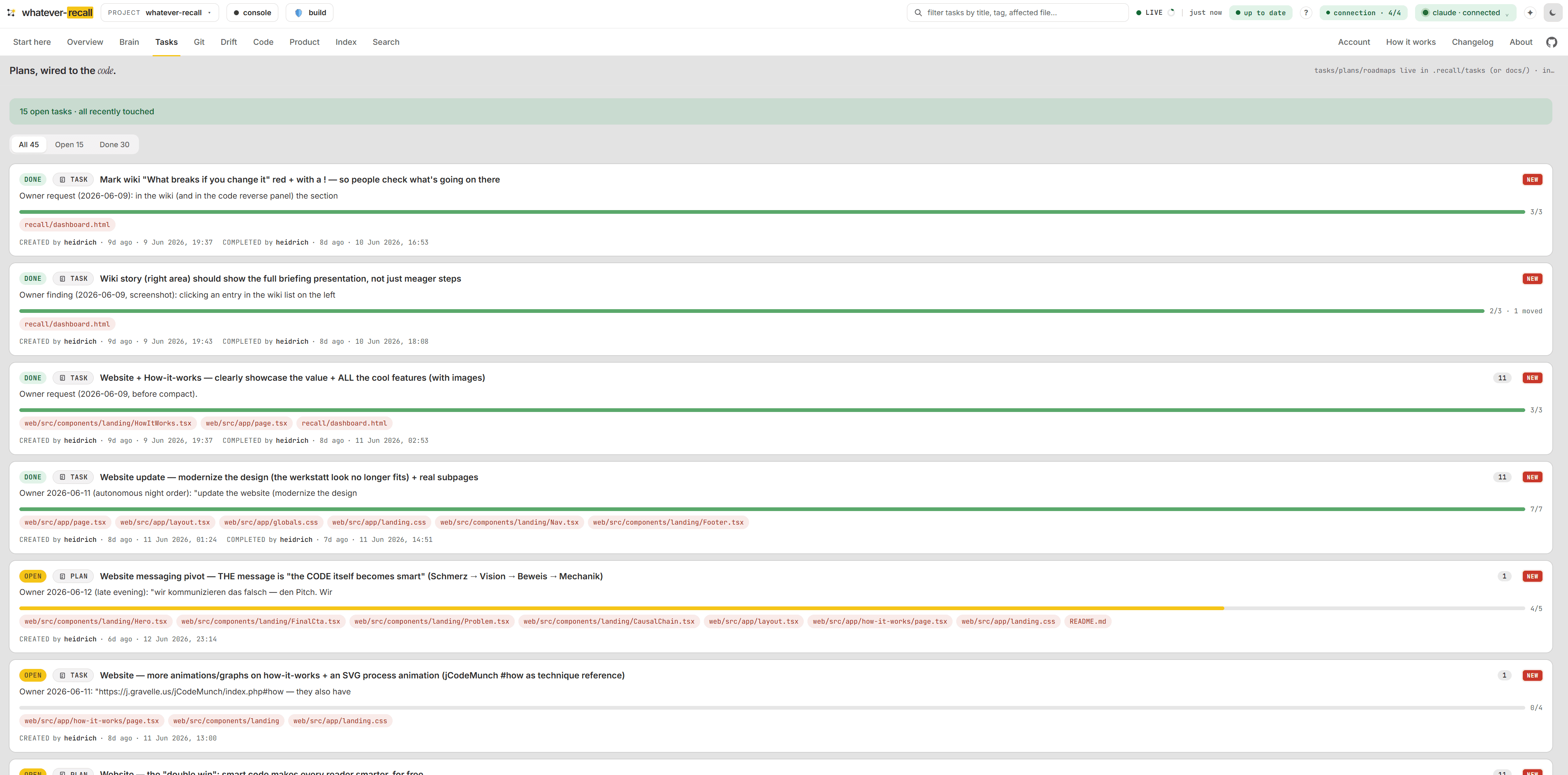
The local dashboard makes the whole memory visible — any time, read-only, zero tokens. Causal chains, plans & tasks, the drift light, the wiring in your code, and the decisions behind it. One running view of every capability. Nothing leaves your machine.
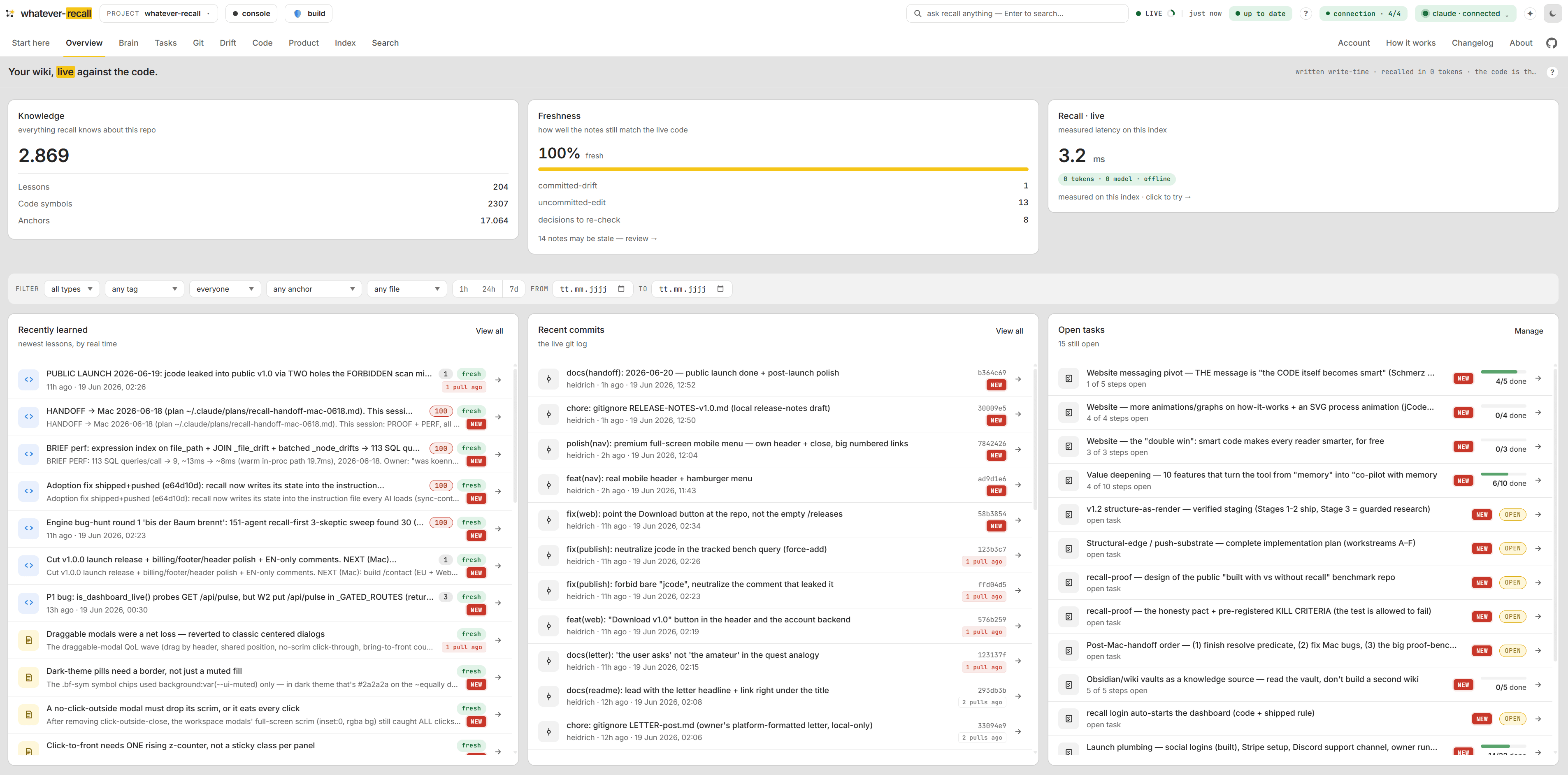


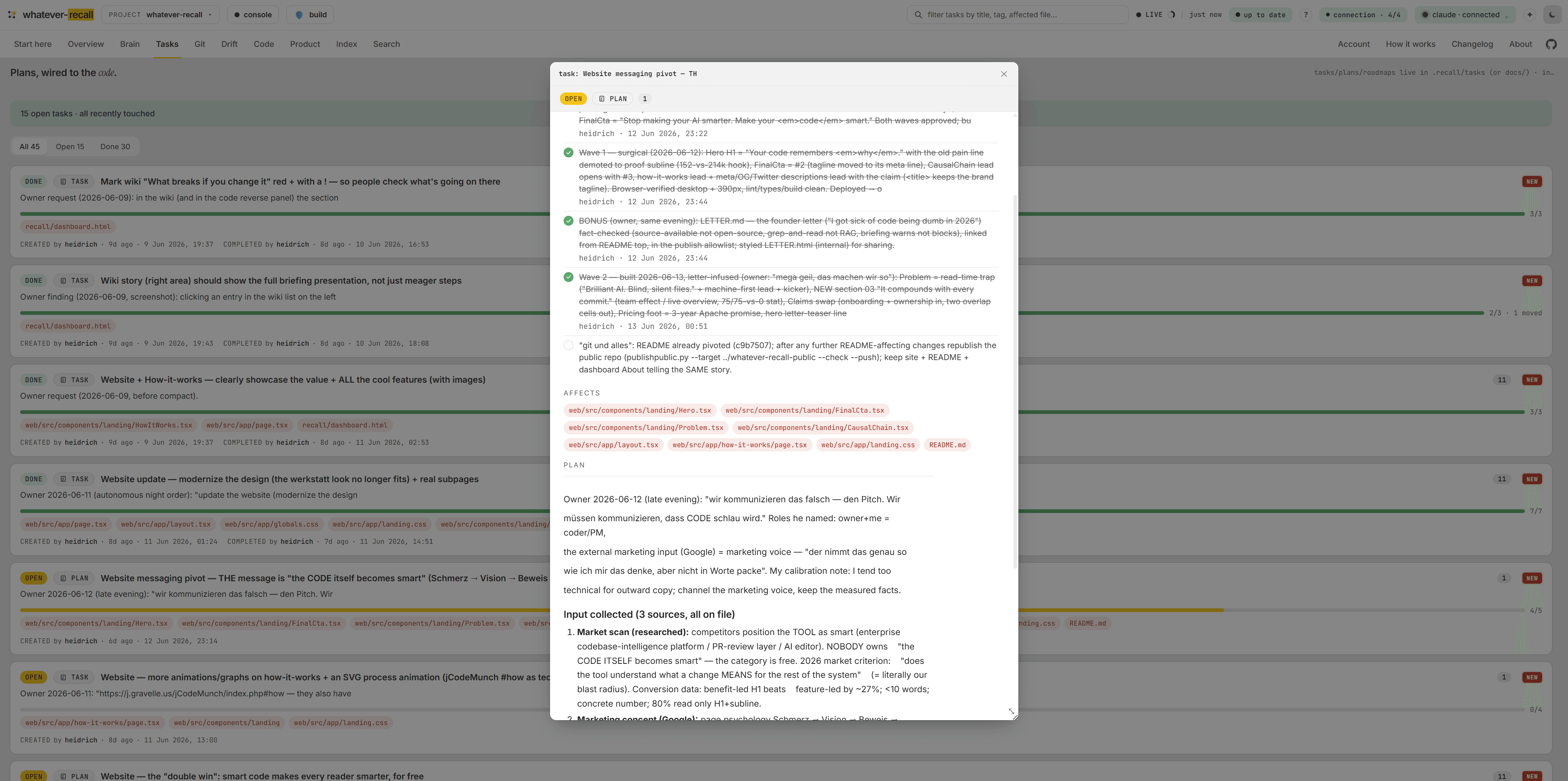
The live pulse — knowledge, freshness, recall.
Your wiki measured against the code: knowledge, a freshness score and recall at a glance, with the latest lessons, commits and open tasks streaming in. Derived from the repo, always current, zero tokens to read.
Two views on the
same result.
The AI reads raw data — but you get a presentation. Both render from a single search result with zero tokens: dumb template code, never the model. Columns to scan, or a living map to explore. Every file path is clickable — open it and a pre-edit briefing sits above the code; a breadcrumb lets you step back through wherever you came from. Time and git make it move.
RLS cut-over lesson
Phase 2.4 decision
test locks it
2 days ago · cut-over
4 days ago · ADR
3 wks ago · check freshness
Smart for free.
Brilliant on purpose.
You're never forced to spend a token. Bootstrap gives you a working memory for nothing. Power Mode is a deliberate upgrade — and every stamp it writes is reversible, tagged by origin (bootstrap · power · live · human). Undo anything, anytime.
Bootstrap
Point recall at your repo. It indexes git, code and existing docs token-free — instant base intelligence. Nothing to opt into, nothing to pay.
Power Mode
A conscious choice. The AI reads the hotspots, understands them, and stamps richer nodes — the real why, synonyms, sharper links. Costs tokens once. Fully reversible.
Living memory
From then on every commit auto-wires new links — even human commits, retroactively. The graph compounds: less effort over time, more precision. It only gets smarter.
Even the AIs that
can't see your disk.
A browser-based AI can't read your local code or git history. So a tiny local bridge does — and only the finished 3-level answer ever leaves your machine, never the code. The website is the gatekeeper: it checks your plan and token, the bridge does the reading. Two doors, both live: a browser AI reads over the HTTP bridge, while a local AI (Claude Code, Cursor, any MCP client) gets recall natively through 14 MCP tools — no copy-paste.
When you contradict
the record, it knows.
A memory rots because nobody notices when reality diverges from it. recall notices the instant you write. If your change contradicts a pinned note, it flags the drift and offers the fix — you approve, and the truth stays current. A sprint plan that's always up to date.
Your write's anchors are recalled against the record. High overlap + opposite meaning = drift. Caught at write-time, not in a review three weeks later.
recall proposes the fix — update the note, or supersede it with a new one that links back (supersedes →). The old decision stays in history, never lost.
Nothing changes without your OK. You approve, recall re-stamps to the new SHA, and the graph is true again. The plan is, by construction, always current.
“You've done this
before. It bit you.”
recall isn't a linter — it won't invent new bugs. But the moment you start repeating a mistake you already documented, it puts the old trap and its fix in front of you, in microseconds. The owner's first rule made mechanical: never make the same mistake twice.
A smart AI greps a name it invented.
Smart, self-aware code knows it.
recall fixes the guess to your repo's real vocabulary before the search — because it's the only thing that recorded what you actually call things.